How We Build a Beat Book
Collect News Stories
Before generating a beat book, we assemble a corpus of news stories to base it off of. Currently, we scrape the RSS feed of Chicago Public Media and rely on their stories to test our beat book builder software. Derek, our professor, set up a scraper that collects each day's published stories and outputs them in JSON format.
Pass JSON to Beat Book Builder Software
We take the corpus of stories (in JSON format) and upload it into our beat book builder software. From there, the following pipeline runs:
- An embedding model, OpenAI's
text-embedding-3-small, embeds each story's content, which lets us group the corpus into clusters of topics. - A text model,
gpt-5-mini, generates human-readable labels for those topic clusters (e.g., "crime," "local politics," "Chicago sports"). -
The topics are passed to our main agent model,
Claude Sonnet 4.6. This model is instructed to evaluate the given topics and ask the reporter a series of questions to gauge what they want their beat book to provide. Here's a screenshot of what this looks like: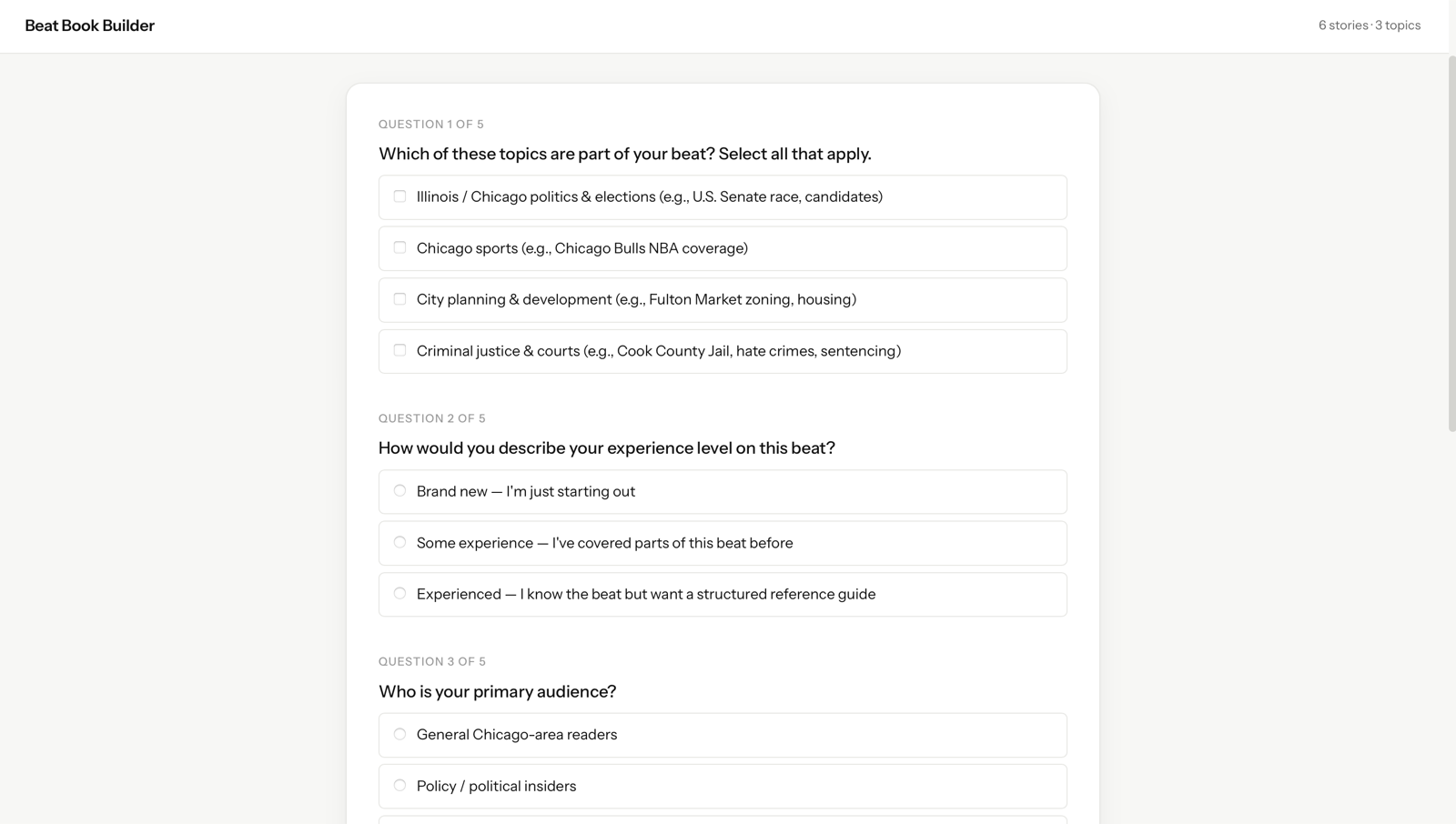
- Once the reporter answers these questions, the agent begins reading relevant stories, taking notes and assembling a first draft of the beat book. It's instructed to take the reporter's answers into account while constructing the guide.
- After the agent finishes its draft, a separate "research" agent built with
Claude Opus 4.7reads over the first draft alongside the reporter's answers to the initial questions, then thinks of ways to pull in additional data and context about the beat book topic from the web. This research agent is given a sandboxed computer environment to write code in, allowing it to create its own Python scrapers, execute terminal commands, and so on, in a safe manner. It's almost like we include a miniature "Claude Code" within our beat book, purpose-built for finding additional context from the internet and rewriting parts of the draft into a finalized version, hydrated with the data it finds. -
Finally, we package the final beat book into a webpage by converting markdown into HTML through a script we run. An embedding-based process also runs over the outputted beat book and converts sentences with high semantic similarity to a source story into inline citations — clickable links that open the original source material so a reporter reading the beat book can verify the content is accurate. This process is imperfect and sometimes produces citations to unrelated articles, but for the most part it's a useful safeguard against hallucinations from the earlier models. Here's what that looks like:
- The resulting product is a beat book that's viewable online, complete with clickable inline citations. Here's a link to an example one for Talbot County, MD.
